1. 乐观锁和悲观锁
为什么需要使用锁机制:在多用户操作数据库的时候(Java的多线程),有可能发送数据增删查改的冲突,例如某一时刻,同时两个用户操作对数据库的某一个变量num + 1。两个用户同时读取num = 1,然后用户A进行了num + 1,用户B也进行了num + 1,此时的num想要的结果应该为num = 3,但是num的结果却是2。
以MySQL更新操作为例:
A:update test set num = num + 1 where name = ‘wsk’;
B:update test set num = num + 1 where name = ‘wsk’;
在并发的情况下,数据库同时执行这2条更新语句,就有可能发生。
这就导致了数据修改不一致而发生了冲突-更新丢失。
还有一种情况,用户A执行更新操作,用户B执行读取操作,当用户A在更新数据的时候,将num更新为2,在这个更新的过程中,用户B读取数据,读取到了num = 1,而此时的num结果应该为2,所以B读取到的数据不正确,这就导致了脏读。
还是以MySQL为例子:
A:update test set num = num + 1 where name = ‘wsk’;
B:select num from test where name = ‘wsk’;
为了解决这些问题,所以加入了锁机制。
锁机制
乐观锁:顾名思义,就是比较乐观的想法,假设在操作的时候,并不会发生数据的冲突,只有在提交操作时检查是否违反数据的完整性。乐观锁并不能解决脏读的问题。还是上面的例子,在A更新的过程中,将num更新为2后,又更新为1,此时B读取到的数据还是1,判断num的值并没有被改变过,所以发生了脏读的可以。 (CAS和ABA问题)
A:update test set num = num + 1 where name = ‘wsk’; update test set num = num - 1 where name = ‘wsk’;
B:select num from test where name = ‘wsk’;
实现:基于数据版本(Version)记录机制实现-为表增加一个版本号或者时间戳。当读取数据的时候,将版本号一同读取出来,然后在更新的时候,将版本号+1。当提交更新操作的时候,判断版本号是否一致,如果一致,则更新,如果不一致,则拒绝更新。
A:set @version = (select version from test where name = ‘wsk’);
update test set num = num + 1,version = version + 1 where name = ‘wsk’ and version = @version;
通过版本号进行判断
B:set @version = (select version from test where name = ‘wsk’);
update test set num = num + 1,version = version + 1 where name = ‘wsk’ and version = @version;
如果A操作和B操作都已经读取到了version为1,A操作的更新操作比B操作快一些,此时version已经被更新为2,此时进行B操作,由于version不一致,导致B操作的更新失败。
悲观锁:在操作的时候,假设可以会发生数据冲突,屏蔽其他的操作,只允许当前操作。
实现:大多数情况下,一般是依靠数据库的锁机制实现的,即在该sql语句后加上“for update”字样。eg:select num from test where name = ‘wsk’ for update; 在执行该语句的时候,数据库自动为操作加锁,只有当该语句执行完成后才释放锁。
结论
乐观锁使用场景是写操作比较少和高并发的情况下,即冲突发生比较少和性能要求比较快,这样可以省去了锁的开销,加大了系统的吞吐量。如果系统的并发量不大,并且不允许出现脏读的情况,则可以考虑使用悲观锁。
2. InnoDB和MyISAM
MySQL5.5以后,默认使用InnoDB。
区别:
来源:https://blog.csdn.net/lc0817/article/details/52757194
存储结构:
MyISAM:每个MyISAM在磁盘上存储成3个文件,第一个文件名是以表的名字开始,扩展名支出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD(MYData)。索引文件的扩展名为.MYI(MYIndex)。
InnoDB:所有的表都存储在同一个存储的数据文件中(可能是多个文件,有可能是独立的表空间文件),InnoDB的大小只受限与操作系统文件的大小,一般为2GB。
存储空间
MyISAM:可以被压缩,存储空间比较小。支持3种不同的存储格式:静态表(默认,但是数据末尾不能有空格,会被自动去掉),动态表,压缩表。
InnoDB:需要更多的内存和存储,他会在主内存中建立专用的缓冲区用于高速缓冲数据和索引。
可移植性,备份和恢复
MyISAM:数据是以文件的形式存储的,所以在跨平台的数据转移中会比较方便。在备份和恢复的时候可以单独对某一个表进行操作。
InnoDB:提供拷贝数据文件、备份binlog或者使用mysqldump。
事务
MyISAM:强调的是性能,每次查询具有原子性,所以执行速度比InnoDB更快,但是不支持事务。
InnoDB:提供事务支持,外键等。
AUTO_INCREMENT
MyISAM:可以和其他字段一起建立索引。索引的自增列必须是索引,如果是组合索引,自增列可以不用是第一列,可以根据前几列进行排序后递增。
InnoDB:必须包含只有该字段的索引。引擎的自增列必须是索引,如果是组合索引也必须是组合索引的第一列。
表锁差异
MyISAM:支持表级锁,用户在操作MyISAM表时,select,update,delete,insert等操作的时候,会自动锁表。
InnoDB:支持事务和行级锁(最大特色)。行锁大幅度提供了多用户并发的性能。但是该行锁,只有在where是主键的时候,才是有效的,非主键的where会锁全表。
全文索引
MyISAM:支持FULLTEXT类型的全文索引。
InnoDB:不支持FULLTEXT类型的全文索引,但是可以使用sphinx插件支持全文索引,而且效率更快。
表主键
MyISAM:运行使用没有任何索引和主键的表存在,索引保存的都是保存行的地址。
InnoDB:如果没有设置主键或者非空唯一索引,就会自动生成一个6字节的主键(不可见),数据是索引的一部分,附加索引保存的是主索引的值。
表的具体行数
MyISAM:保存有表的总行数,select count(*) from table直接获得该值。
InnoDB:没有保存,使用上面的SQL会直接遍历整个表,消耗大,但是如果使用where条件后,MyISAM和InnoDB处理方式是一样的。
CURD操作
MyISAM:如果执行大量的select操作,MyISAM效果更好。删除数据表的时候,直接drop表,然后create新表。
InnoDB:如果需要执行大量的insert和update,出于性能的考虑,应该使用InnoDB。delete从性能上来说,InnoDB会更好,但delete from table时,InnoDB不会重新建表,而是一行一行的删除,在数据量比较打的时候,会很慢。所以,最好使用truncate table命令。
外键
MyISAM:不支持外键。
InnoDB:支持
3. 数据库优化
explain
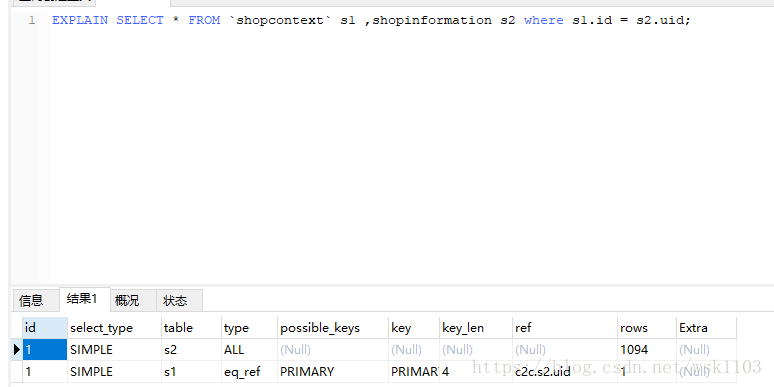
列解释:
select_type:select查询的类型,主要是区别普通查询、联合查询和子查询等复杂查询
table:输出的行所引用的表
type:联合查询所使用的类型(这是一个比较重要的指标。)性能依次为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL。一般来说,查询至少达到range级别,最好是达到ref级别。
possible_keys:MySQL是使用哪些索引。如果为空,则表示没有使用索引,这个时候可以通过检查where条件或者建立合适的索引。
key:显示MySQL实际使用的键。如果没有索引被选择,键是null。
key_len:显示使用的键的长度。如果键是null,那么长度也是null。
ref:表示哪个字段或者常数和key一起被使用。
rows:表示需要遍历多少数据才能找到,在InnoDB上是不正确的。
Extra:如果是only index,表示只用索引树检索信息;如果是where used,表示使用了where条件;如果是impossible where表示用不着where,一般是查不出来的;using filesort或者using temporary的话,where和order by
的索引经常无法一起使用,如果使用where索引,那么在order by的时候,会引起using filesort。这就需要比较先过滤再排序或者是先排序再过滤。
常见名词:
using filesort:需要额外的一次传递,以找出使用合适的顺序检索。
using index:从只使用索引树中的信息之间检索相应的信息。
using temporary:为了解决查询,需要创建一个临时表来容纳结果。
ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。
all:全表扫描,没有使用索引。性能差。
index:与all类似,扫描索引树。但是比all快,因为索引文件比数据文件小。
simple:简单的查询,不需要使用union或者子查询。